
SimpleSSD is a high-fidelity SSD simulation framework designed towards an educational purpose. It builds up a complete storage stack from scratch, models all detailed characteristics of SSD internal hardware and software, provides promising simulation speed, and can be integrated into publicly-available full system simulators. We have verified our simulation framework with commercial SSD and our experiments demonstrate high accuracy of simulation results.
PROTOTYPES (hide)
We are always interested in offering a valuable research vehicle to understand how the evolution of emerging non-volatile memory technologies and massively parallel chip architectures can be guided by close-coupled feedback with the design of the application, algorithms, and hardware together. So far, we built up several hardware prototypes, FPGA-based memory controllers and simulation frameworks that capture low-level memory characteristics.
Revolutionizing Memory Capacity and Processing over Arrays

We are excited to announce the release of our latest innovation, the 4th generation high-performance accelerator and memory arrays. With this breakthrough technology, we can now support the world's largest memory capacity while enabling near data processing capability. This development marks a significant milestone in our pursuit of more advanced and practical hardware and system research, specifically in the areas of AI and ML acceleration, cache coherent interconnect, and memory expansion. We welcome individuals who are passionate about pioneering cutting-edge research on computer architecture and operating systems (OS) to join us on this exciting journey.
The World-First CXL-Based Disaggregated Storage Class Memory Pool


CAMEL is proud to announce the world's first CXL controllers and SCM-based disaggregated memory cards (DMC) are now secure. Our team is currently designing a cutting-edge disaggregated memory switch, boasting over 500 storage class memory modules (SCM) that can be seamlessly scaled up by simply adding multiple pooling switches. If you share our passion for exploring the frontiers of reliable, robust, safe, and intelligent computer and memory architecture, we warmly invite you to join us on this exhilarating quest.
CAMEL's Open Source Licence Software

SimpleSSD [website]
Open-Source Licenced Educational SSD Simulatior for High-Performance Storage and Full-System Evaluations
PUBLICATIONS: DockerSSD: Containerized In-Storage Processing and Hardware Acceleration for Computational SSDs (HPCA'24) Amber: Enabling Precise Full-System Simulation with Detailed Modeling of All SSD Resources (MICRO'18) FlashShare: Punching Through Server Storage Stack from Kernel to Firmware for Ultra-Low Latency SSDs (OSDI'18) SimpleSSD: Modeling Solid State Drive for Holistic System Simulation (IEEE CAL) MORE RELATED WORK (SimpleSSD 1.0) MORE RELATED WORK (SimpleSSD 2.0)

OpenExpress [paper] [download]
Fully Hardware Automated Open Research Framework for Future Fast NVMe Devices
NVMe is widely used by diverse types of storage and nonvolatile memories subsystems as a de-facto fast I/O communication interface. Industries secure their own intellectual property (IP) for high-speed NVMe controllers and explore challenges of software stack with future fast NVMe storage cards.
PUBLICATIONS: DockerSSD: Containerized In-Storage Processing and Hardware Acceleration for Computational SSDs (HPCA'24) Hello Bytes, Bye Blocks: PCIe Storage Meets Compute Express Link for Memory Expansion (CXL-SSD) (HotStorage'22) OpenExpress: Fully Hardware Automated Open Research Framework for Future Fast NVMe Devices (USENIX ATC'20)

GraphTensor [paper] [download]
Comprehensive GNN-Acceleration Framework for Efficient Parallel Processing of Massive Datasets
GraphTensor is a comprehensive acceleration framework for GNN computation that supports efficient parallel processing on large graphs. GraphTensor offers a set of easy-to-use GNN-specific programming interfaces, enabling its users to implement diverse GNN models. Supporting parallel embedding processing through a vector-centric approach and applying pipeline preprocessing, GraphTensor resolves the performance issues in conventional frameworks such as PyG and DGL.
PUBLICATIONS: GraphTensor: Comprehensive GNN-Acceleration Framework for Efficient Parallel Processing of Massive Datasets (IPDPS'23)

OpenNVM [website] [download]
An Open-Sourced FPGA-based NVM Controller for Low Level Memory Characterization
OpenNVM can cope with diversified memory transactions and cover a variety of evaluation workloads without any FPGA logic block updates. In our design, while evaluation scripts are managed by a host, all the NVM-related transactions are handled by our FPGA-based NVM controller connected to the hardware circuit board that can accommodate different types of NVM product and our custom-made power measurement board. This open scheme has been developed to generate exhaustive, empirical data of emerging non-volatile memory in a configured, programmable FPGA based hardware prototype in order to serve the area in research on memories, especially non-volatile type.
PUBLICATIONS:FlashAbacus: A Self-governing Flash-based Accelerator for Low-power System (EuroSys'18) NearZero: An Integration of Phase Change Memory with Multi-core Coprocessor (IEEE CAL'17) OpenNVM: An Open-Sourced FPGA-based NVM Controller for Low Level Memory Characterization (ICCD'15) MORE RELATED WORK

NANDFlashSim [website] [download]
A cycle-accurate and hardware-validated NAND flash simulation model (open source project)
NANDFlashSim is a flash simulation model, decoupled from specific flash firmware and supports detailed NAND flash transactions with cycle accuracy. This low-level simulation framework can enable research on the NAND flash memory system itself as well as many NAND flash-based devices such as Flash-based SSD, eMMC, CF memory card, mobile NAND flash mediums etc. We have been evaluated a hundred thousands of NANDFlashSim instances on NERSC Hopper and Carver supercomputers.
PUBLICATIONS: NANDFlashSim: High-Fidelity, Micro-Architecture-Aware NAND Flash Memory Simulation (ACM Transactions on Storage (TOS)) HIOS: A Host Interface I/O Scheduler for Solid State Disks (ISCA'14) Sprinkler: Maximizing Resource Utilization in Many-Chip Solid State Disks (HPCA'14) Triple-A: A Non-SSD Based Autonomic All-Flash Array for Scalable High Performance Computing Storage Systems (ASPLOS'14) Physically Addressed Queueing (PAQ): Improving Parallelism in Solid State Disks (ISCA'12) Understanding System Characteristics of Online Erasure Coding on Scalable, Distributed and Large-Scale SSD Array Systems (MSST'12) MORE RELATED WORK

Open Storage Trace [website]
Storage traces are widely used for storage simulation and system evaluation. Since high performance SSD, flash array and NVM systems exhibit different I/O timing behaviors, the traditional traces need to be revised or collected on relatively modern systems. To address this, we are collecting different types of traces with many different combinations of devices and systems. Our trace repository distributes traces collected on Kandemir, Wilson, John and Donofrio machines under different types of parallel file systems such as lustre and ceph. Hope that we can secure more traces, which can help storage system and architecture communities to make better and easy-to-reproduce research.
PUBLICATIONS: PEN: Design and Evaluation of Partial-Erase for 3D NAND-Based High Density SSDs (FAST'18) TraceTracker: Hardware/Software Co-Evaluation for Large-Scale I/O Workload Reconstruction (IISWC'17) Understanding System Characteristics of Online Erasure Coding on Scalable, Distributed and Large-Scale SSD Array Systems (IISWC'17) MORE RELATED WORK

FlashGPU [download]
FlashGPU is a MacSim-based GPU simulation model that integrates with SimpleSSD. This research framework can be basically used for exploring an emerging GPU platform that would employ flash wihtin its discrete device. The current version of FlashGPU replaces global memory with Z-NAND that exhibits ultra-low latency. It also architects a flash core to manage request dispatches and address translations underneath L2 cache banks of GPU cores. While Z-NAND is a hundred times faster than conventional 3D-stacked flash, its latency is still longer than DRAM. We expect that many different types of persistent memory subsystems, algorithms, controllers can be researched to address such long latnecy issues on flash in cases where ones require putting flash into massive GPU core network.
PUBLICATIONS: ZnG: Architecting GPU Multi-Processors with New Flash for Scalable Data Analysis (ISCA'20) FlashGPU: Placing New Flash Next to GPU Cores (DAC'19) MORE RELATED WORK

SystemC-based DRAMSim2 [report] [download]
SystemC interface converter (SCIC) enables DRAMSim to be integrated with comprehensive pin-level system simulation models. SCIC manages protocol difference between the DRAMSim and SystemC interface. SCIC also provides storage resources for modeling data movement. Additionally in this project, a pin-level protocol (Transaction Level 0) is introduced it to the memory system model of DRAMSim; therefore, the memory system can be harmonized to other simulators that employ SystemC or HDL simulation.
PUBLICATIONS: SCIC: A System C Interface Converter for DRAMSim (Lawrence Berkeley National Laboratory Techinical Report)
CAMEL's Hardware Prototypes

AutoGNN [paper]
Dynamically reconfigurable graph preprocessing accelerator for GNN workloads on various datasets

DirectCXL [paper]
World's first CXL 2.0-based full-system memory pooling framework including CXL switch, CXL CPU, and Memory expander
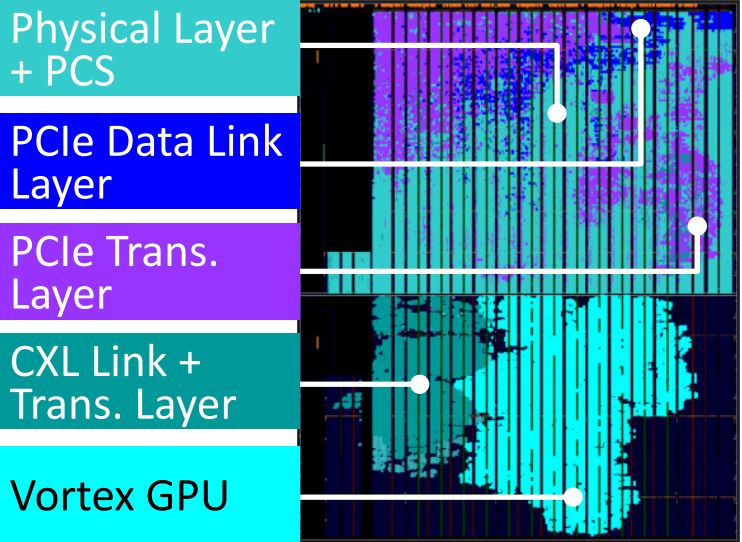
CXL-GPU [paper]
GPU storage expansion solution utilizing sub-two digit nanosecond latency CXL controller
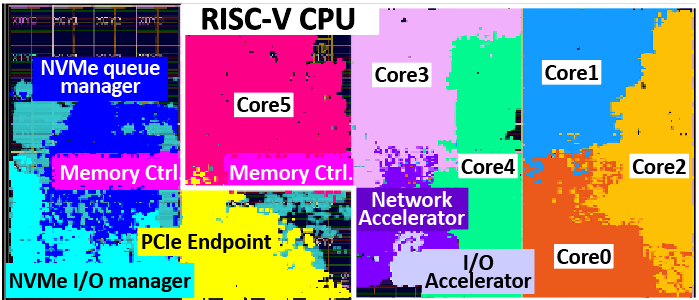
DockerSSD [paper]
Fully-flexible computational SSDs with OS-level virtualization and hardware acceleration.

CXL-ANNS [paper]
Software-hardware collaborative memory disaggreation and computation for billion-scale approximate nearest neighbor search.
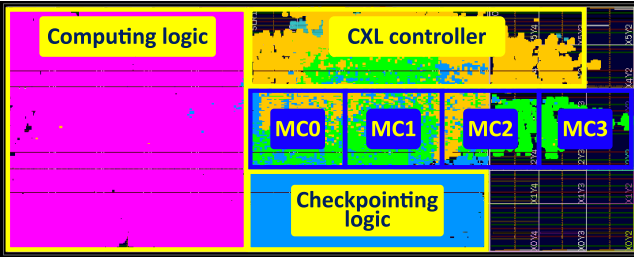
TrainingCXL [paper]
Failure tolerant recommendation system training architecture on persistent memory disaggregated over CXL.
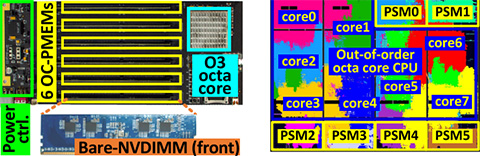
LightPC [paper]
Co-designed hardware and software for energy-efficient full system persistence.
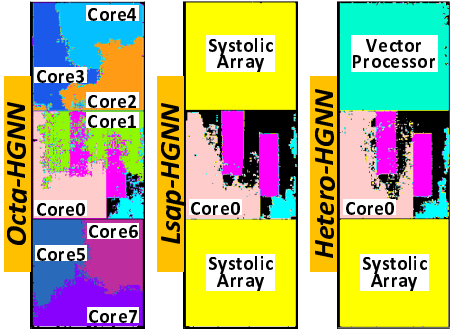
HolisticGNN [paper]
Hardware/software co-programmable framework for computational SSDs to accelerate deep learning service on large-scale graphs.
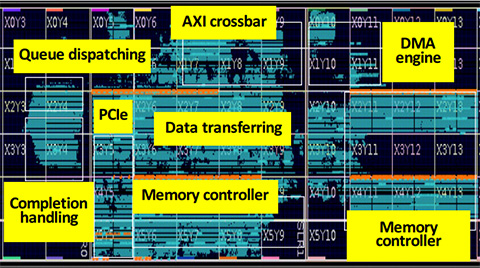
OpenExpress [paper]
Fully hardware automated open research framework for future fast NVMe devices.
Solid State Drive Simulator/Emulator

FLASHWOOD
Comprehensive Large-scale NVRAM Storage Simulation Framework
In this simulation framework, NVRAM software stack on multi-channel architecture are fully implemented, and diverse parameters/algorithms are reconfigurable (e.g., buffer cache, NVMHCIs, flash drivers, flash translation layers, physical layouts). Hardware components are emulated in a cycle-level by multiple NANDFlashSim instances, DRAM simulation instances, and virtual channel and controller modules. Flashwood can also evaluate dynamic energy and power consumption by catching all the different components' activities. The code for the flash software in the framework and device simulation code are around two hundreds thousand of lines and ten thousand of lines, respectively.

CoDEN
A Hardware/Software CoDesign Emulation Platform for SSD-Accelerated Near Data Processing
CoDEN is a novel hardware/software co-design emulation platform, which not only offers flexible/scalable design space that can employ a broad range of SSD controller and firmware policies, but also capture the details of entire software/hardware stacks for SSD-accelerated near data processing. Our CoDEN can be connected to a host through PCI Express (PCIe) interface, a high performance memory bus, and recognized by the host as a real SSD storage device.

ASURA
SSD emulation kernel driver
The SSD emulation kernel driver provides a logical volume to native file systems (e.g., Windows NTFS, EXT4) as a pseudo SSD device. Virtual channels and cycle-level NAND flash simulation instances of Asura model the actual runtime in cycle accurate by hooking kernel I/O dispatch routines. To enable large-scale SSD emulation, the driver only stores metadata of kernel modules, data of flash firmware and device simulation models -- omits actual data contents. In addition, Asura can be initiated as multiple driver instances in order to emulate an SSD RAID system. Asura has been implemented by a filter driver (WDM) for Windows (NTFS) and loadable kernel module for Linux (EXT4).
