
Dr. Miryeong Kwon has been honored with the prestigious KAIST Outstanding PhD Dissertation Award
04.01.2024

We are delighted to announce that Dr. Miryeong Kwon has been honored with the prestigious KAIST Outstanding PhD Dissertation Award (최우수 박사졸업논문 총장상), a recognition bestowed upon the highest-ranking Ph.D. candidate across all departments within KAIST. Dr. Kwon's academic portfolio is impressive, encompassing 40 publications that span critical advancements in high-performance storage/flash technologies and CXL cache coherent interconnect technologies.
Her contributions extend far beyond her remarkable scholarly achievements. Dr. Kwon embodies a set of exemplary characteristics that have positively influenced our team dynamics, fostering a collaborative and joyful environment within CAMEL. Her presence and leadership have catalyzed significant growth and success in our lab, and her unwavering dedication and care have been instrumental in our collective accomplishments.
Dr. Kwon's journey through her Ph.D. has set a benchmark that transcends the conventional expectations of doctoral research. Her capacity to blend high-caliber research with genuine, positive team interactions is a testament to her comprehensive excellence.
As CAMEL continues to flourish, we attribute a considerable portion of our progress to Dr. Kwon's efforts. Her trajectory in academia and beyond holds immense promise, and we are confident that her future endeavors will lead to outstanding contributions to any team or project she chooses to engage with. Our heartfelt congratulations to Dr. Kwon, along with our anticipation for her continued success, reflecting our belief in her potential to set new standards of excellence across various domains. Congratulations!
Donghyun and Miryeong's SSD Virtualization Research Gains Acceptance at HPCA'24
10.23.2023



Donghyun and Miryeong's groundbreaking work on computational SSD virtualization has received recognition with its acceptance by HPCA'24, held in Edinburgh, Scotland. The concept of processing data directly within storage presents an energy-efficient approach to handle vast datasets. Yet, the practical implementation of this renowned task-offloading model in real-world systems has encountered challenges. These hurdles are primarily attributed to suboptimal performance and numerous practical obstacles, encompassing limited processing prowess and heightened vulnerabilities at the storage level.

In our research, we introduce DockerSSD, a novel in-storage processing (ISP) model. This model is characterized by its ability to seamlessly run a diverse range of applications proximate to flash storage without necessitating modifications at the source level. DockerSSD pioneers lightweight OS-level virtualization within contemporary SSDs. This innovation ensures the intelligent functioning of storage in sync with the prevailing computing ecosystem, further enhancing the speed of ISP. In lieu of crafting a unique, vendor-specific ISP for offloading purposes, DockerSSD leverages existing Docker images. It establishes containers as autonomous execution entities within storage, facilitating real-time data processing at its source. To realize this, we engineered a fresh communication approach and virtual firmware. These elements collaboratively facilitate Docker image downloads and manage container operations, all while preserving the integrity of the current storage interface and runtime. Our design also incorporates automated container-associated network and I/O data pathways on hardware, optimizing ISP speeds and minimizing latency. Our empirical evaluations reveal DockerSSD's superior performance, clocking in at 2.0× faster speeds compared to conventional ISP models, while consuming 1.6× and 2.3× less power and energy, respectively.
It is noteworthy to mention that this year's paper acceptance rate for HPCA stands at a mere 18% — a significant decrease from previous years. A heartfelt congratulations to Donghyun and Miryeong on this remarkable achievement!
CAMEL has been selected for 2023 Samsung Future Technology Development Program: Venturing Deeper into Hyperscale AI
10.16.2023

We have been selected to participate in Samsung's Future Technology Development Program. This selection comes with funding for our research, entitled "Software-Hardware Co-Design for Dynamic Acceleration in Sparsity-aware Hyperscale AI." In recent years, Hyperscale AI models like MoE, autoencoders, and multimodal learning have seen increasing adoption, particularly in extensive model-driven applications such as ChatGPT. Recognizing that the computational characteristics of these models often change throughout the training process, we have proposed a variety of acceleration techniques. These techniques combine innovative software technologies, specialized algorithms, and hardware accelerator configurations. A significant insight has been the limitation of current training platforms in adjusting for variable data sparsity and computational dynamics across model layers, which inhibits effective adaptive acceleration. To remedy this, we have developed a dynamic acceleration method that can identify and adapt to shifts in computational traits in real-time. This research has potential implications not only for Hyperscale AI but also for the broader field of deep learning and the emerging services industry. Our objectives include the development of practical hardware models and the provision of open-source software solutions.
Since its inception in 2013, Samsung's Future Technology Development Program has invested KRW 1.5 trillion to foster technological innovation crucial for future societal advancements. The program has consistently supported initiatives in foundational science, innovative materials, and ICT, favoring particularly those that are high-risk but promise substantial returns. We have collaborated with Samsung FTDP foundation since 2021 on a project focused on accelerating Graph Neural Networks (GNNs). As we delve deeper into the Hyperscale AI landscape, we extend our gratitude for this opportunity and look forward to impactful contributions.
Distinguished Lecture on CXL Technology Hosted by Peking University
09.20.2023

We are thrilled to announce an upcoming distinguished lecture that promises to be a seminal event in the realm of Electrical and Computer Engineering. Hosted by Peking University, the lecture has garnered interest from top-tier institutions across China, including but not limited to Tsinghua University, Huazhong University of Science and Technology, Xiamen University, Sun Yat-sen University, Shanghai Jiao Tong University, and the Chinese Academy of Science. The talk, entitled "Revolutionizing Data Centers: The Role of CXL Technology," aims to shed light on the advancements and implications of Compute Express Link (CXL) in the contemporary computing landscape.
The distinguished lecture will be held on a date and at a venue to be announced, and it will be available in both virtual and in-person formats. The talk is not just another technical presentation; it seeks to engage its audience in a nuanced discussion about the sweeping changes that CXL technology is bringing to the world of computing. CXL is a cutting-edge communication protocol that has been designed to streamline interactions between central processing units and specialized computing units like field-programmable gate arrays and graphics processing units. Its role in enhancing the efficiency of data centers and accelerating the pace of advancements in sectors such as artificial intelligence and machine learning cannot be overstated. One of the most compelling aspects of this event is the breadth of its target audience. The lecture is meticulously designed to cater to a wide spectrum of professionals and academicians. Whether you are a hardware engineer, a software developer, a research scientist, a data center operator, or even a student in a related field, the insights offered in this lecture are poised to be invaluable. Beyond merely outlining the technical features and benefits of CXL technology, the speaker will also focus on its real-world applications and its potential to drive future innovations.
In summary, this distinguished lecture offers a rare and comprehensive overview of CXL technology, positioned within both a technical and practical framework. It aims to bring together the brightest minds in the field for a discourse that could very well shape the future of next-generation computing technologies. We earnestly look forward to your participation.
Breaking Down CXL: Why It's Crucial and What's Next
07.22.2023

At SIGARCH'23, we had the opportunity to deliver an invited talk titled "Breaking Down CXL: Why It's Crucial and What's Next." During this presentation, we extensively dissected the ins and outs of Compute Express Link (CXL) technology, highlighting its relevance and the present status of its advancement. CXL is a potent interconnect standard offering high-speed, low-latency communication between CPUs and diverse accelerators such as FPGAs and GPUs. It allows these devices to share memory space and maintain cache coherence, resulting in swift data access and efficient processing of intricate tasks. Our exploration of CXL began from its genesis, the CXL 1.0 specification, and continued through its successive iterations, including the recently launched CXL 3.0. We emphasized the unique features of each iteration, differences among them, and the advantages of CXL compared to other interconnect standards. Beyond just the technicalities of CXL, we also navigated its real-world impact. We specifically addressed how CXL is deployed in large-scale data centers and its role in fostering innovation in areas like artificial intelligence and machine learning. Overall, this talk served as a platform to share a thorough understanding of CXL technology, from its fundamental principles to its practical applications.
Memory Pooling over CXL and Go Beyond with AI
07.04.2023

We presented an insightful talk at this year's Open Compute Project (OCP) Regional Summit. The presentation, titled "Memory Pooling over CXL and Go Beyond with AI," introduced the concept of Compute Express Link (CXL) with a focus on AI applications. Hosted at the Seoul Convention and Exhibition Center (COEX) and Samsung, the OCP 2023 Regional Summit convened key players from the server, CPU, network, and memory sectors. We were at the forefront, elucidating the technique of Memory Pooling over CXL designed to enhance memory utilization and system performance. Our talk, in alignment with OCP's mission of "Empowering Open", offered fresh insights to help organizations leverage the benefits of open technologies and drive innovation in their fields. For those who missed the live presentation, the session will be available on the OCP's event website. Please check the below for more detailed information.
Check more: [ Info ]
Unleashing the Potential of CXL: Our Exploration and Discoveries
05.25.2023


Recently, we were privileged to receive an invitation from the distinguished Professor Byung-Gon Chun, CEO of FriendliAI at Seoul National University. This invite provided us an esteemed platform to present our novel work on the leading-edge Compute Express Link (CXL) technology. During our exposition, we started off by illustrating a unique software-hardware integrated system aimed at boosting search capabilities for approximate nearest neighbors. This avant-garde solution efficiently utilizes CXL to segregate the memory from host resources, thereby optimizing system efficiency. One of the critical features of CXL is its distant memory characteristics. Despite this, we designed our system to enhance search performance remarkably. We did this by adopting innovative strategies and fully utilizing all accessible hardware. This new approach has shown superior performance in terms of query latency when compared to existing platforms, confirming its efficacy.

In the next part of our discourse, we introduced a resilient system specifically architected for managing voluminous recommendation datasets. We utilized the versatility of CXL to flawlessly amalgamate persistent memory and graphics processing units into a cache-coherent domain. This amalgamation allows the graphics processing units to directly access the memory, thereby negating the need for software intervention. Moreover, this system adopts an advanced checkpointing technique to sequentially update model parameters and embeddings across various training batches. This sophisticated methodology has significantly elevated the training performance and notably reduced energy consumption, thus augmenting system efficiency. As we progress on our journey, we are enthusiastic about encountering more such opportunities to share our expertise and discoveries with the wider tech community. We are perpetually pushing the boundaries, exploring the realms of possibility with state-of-the-art technologies like CXL. Stay connected for more updates on our future endeavors as we continue this exhilarating expedition of innovation and discovery.
Miryeong and Sangwon's expander-driven prefetcher for CXL-SSD has been accepted by HotStorage'23
05.20.2023

We are thrilled to announce that a cutting-edge research paper, penned by Miryeong Kwon and Sangwon Lee, has been accepted at this year's HotStorage conference. We present a groundbreaking solution to a significant challenge in the realm of data storage and memory access. The research centers on the integration of Compute Express Link (CXL) with Solid State Drives (SSDs), a technology capable of scalable access to large memory. However, this capability traditionally comes at a cost, mainly slower speeds compared to Dynamic Random Access Memory (DRAM). To overcome this, we introduce an "expander-driven CXL prefetcher," a novel solution that shifts primary Last Level Cache (LLC) prefetch tasks from the host Central Processing Unit (CPU) to CXL-SSDs. Notably, this approach has been designed with CPU design area constraints in mind, underlining the real-world applicability of this research. Their evaluation results are staggering, revealing that the proposed prefetcher can significantly boost the performance of various graph applications, characterized by their highly irregular memory access patterns. The enhancement reaches up to 2.8 times when compared to a CXL-SSD expanded memory pool without a CXL-prefetcher. This revolutionary research represents a substantial step forward in memory access and storage technology, with the potential to influence various tech industries. We are eager to share their findings with the broader community at this year's HotStorage conference. They welcome fellow researchers, industry experts, and anyone with an interest in this technology, to engage with them during the event. We congratulate Miryeong Kwon and Sangwon Lee on their phenomenal work and eagerly anticipate their presentation at HotStorage. We look forward to seeing the transformative impact their research will undoubtedly have on the future of memory technology. See you at Boston soon!
Junhyeok's work for CXL-augmented ANNS has been accepted by USENIX ATC 2023
04.29.2023


We are thrilled to announce the acceptance of our research paper "CXL-ANNS: A Software-Hardware Collaborative Approach for Scalable Approximate Nearest Neighbor Search" at USENIX ATC, a highly-regarded conference with a rigorous review process and an acceptance rate of only 18%. Our paper proposes a novel approach to approximate nearest neighbor search (ANNS) that leverages the power of both software and hardware to achieve scalability and performance.We utilize compute express link (CXL) technology to separate DRAM from the host resources and place essential datasets into its memory pool, allowing us to handle billion-point graphs without sacrificing accuracy. To address the performance degradation that can occur in CXL systems, our approach caches frequently visited data and prefetches likely data based on graph traversing behaviors of ANNS. Additionally, CXL-ANNS leverages the parallel processing power of the CXL interconnect network to improve search performance even further. The results of our empirical evaluation are impressive, with CXL-ANNS exhibiting 22.9x lower query latency than state-of-the-art ANNS platforms and outperforming an oracle ANNS system with unlimited DRAM storage capacity by 2.9x in terms of latency. We believe that CXL-ANNS will be a game-changer in the field of ANNS, and we are honored to have our work recognized by USENIX ATC. Get ready to revolutionize your ANNS research with CXL-ANNS! See you in Boston, July!
New members of CAMEL present groundbreaking research at Samsung Global Technology Symposium
04.21.2023


Our team was recently invited to present three groundbreaking research projects at the Samsung Global Technology Symposium, an event attended by over 600 engineers and students. These projects, associated with Samsung's innovative social contribution programs (삼성미래기술육성), delved into various aspects of technology with the aim of revolutionizing computation and deep learning. The first project explored a hardware/software co-programmable framework for computational SSDs, while the second examined the use of hardware acceleration to improve preprocessing in graph neural networks. The third project focused on developing a comprehensive GNN-acceleration framework for efficient parallel processing of massive datasets. All of these projects have been published in renowned computer science and engineering conferences and journals. Currently, our team is working on preparing the final framework as a powerful open-source GNN platform, which is set to make its debut at the IPDPS'23 conference in Florida this May. We are proud of our team's accomplishments and look forward to sharing these advancements with the broader scientific and engineering communities.
Revolutionizing Memory Capacity and Processing: Our Latest High-Performance Accelerator and Memory Arrays
03.10.2023


We are excited to announce the release of our latest innovation, the 4th generation high-performance accelerator and memory arrays. With this breakthrough technology, we can now support the world's largest memory capacity while enabling near data processing capability. This development marks a significant milestone in our pursuit of more advanced and practical hardware and system research, specifically in the areas of AI and ML acceleration, cache coherent interconnect, and memory expansion. We welcome individuals who are passionate about pioneering cutting-edge research on computer architecture and operating systems (OS) to join us on this exciting journey.
Opening Talk Invitation to Heterogeneous and Composable Memory Workshop at HPCA'23
02.21.2023


We are delighted to share that our team member (Junhyeok Jang) will be presenting an opening invited talk at the upcoming Heterogeneous and Composable Memory Workshop, to be held in conjunction with HPCA'23 in Montreal, Canada. The talk will showcase our innovative research solution that utilizes the power of CXL 3.0 to efficiently process large-scale recommendation models (RMs) in a disaggregated memory setting while ensuring low overhead and failure tolerance during training. This one-day workshop is set to feature key industry players in the CXL domain such as Microsoft, Intel, and Panmnesia, as well as distinguished academics from KAIST, UCDavis, UMichigan, UToronto, and beyond. We invite you to explore the abstract and program details the workshop website and join us for this exciting event!
Check more: [ Program ]
Emerging CXL Workshop with Leading Industry Experts and Renowned Academics
02.18.2023


We had the honor of participating in a dynamic and engaging CXL workshop, where we joined forces with leading CPU and memory vendors including Intel, AMD, Panmnesia, Samsung, and SK-Hynix. It was an exciting opportunity to engage in high-level discussions regarding the latest trends and innovations in CXL technology, and how these advancements are shaping the future of large-scale data-centric applications. During the workshop, we were presented with valuable insights into the direction that data-centric applications should take, and the ways in which cutting-edge research directions such as near-data processing and AI acceleration are driving innovation in this space. These discussions were both stimulating and thought-provoking, and we are thrilled to have been part of such an insightful event. As we look towards the future, we are excited to continue our involvement with this exciting technology and to be part of future discussions that will shape the development and implementation of CXL technology. The workshop was a true privilege to attend, and we look forward to further engagement in this innovative field.
Invited Talk for Memory Pooling over CXL at Computer System Society 2023
02.07.2023


It was a great time to have an invited talk entitled “Memory Pooling over CXL” at Computer System Society 2023! In the talk, we introduced our history of development and research for CXL and memory expander (2015~2023) with some specific use-cases. We also showed a new type of memory pooling stack and introduced a CXL 3.0 memory expander device reference board we built up from the ground. We are also excited to share more technical details of those and share our vision at a closed CXL working symposium (AMD, Intel, Samsung, and SK-Hynix), this month!
Junhyeok's work for open-source GNN acceleration framework has been accepted by IEEE IPDPS 2023
01.28.2023


We present GraphTensor, a comprehensive open-source framework that supports efficient parallel neural net- work processing on large graphs. GraphTensor offers a set of easy-to-use programming primitives that appreciate both graph and neural network execution behaviors from the beginning (graph sampling) to the end (dense data processing). Our framework runs diverse graph neural network (GNN) models in a destination-centric, feature-wise manner, which can significantly shorten training execution times in a GPU. In addition, GraphTensor rearranges multiple GNN kernels based on their system hyperparameters in a self-governing manner, thereby reducing the processing dimensionality and the latencies further. From the end-to-end execution viewpoint, GraphTensor significantly shortens the service-level GNN latency by applying pipeline parallelism for efficient graph dataset preprocessing. Our evaluation shows that GraphTensor exhibits 1.4× better training performance than emerging GNN frameworks under the execution of large-scale, real-world graph workloads. For the end-to-end services, GraphTensor reduces training latencies of an advanced version of the GNN frameworks (optimized for multi-threaded graph sampling) by 2.4×, on average.
Miryeong's work entitled by failure tolerant training over CXL has been accepted by IEEE Micro 2023
01.08.2023


This paper proposes TrainingCXL that can efficiently process large-scale recommendation datasets in the pool of disaggregated memory while making training fault tolerant with low overhead. To this end, i) we integrate persistent memory (PMEM) and GPU into a cache-coherent domain as Type 2. Enabling CXL allows PMEM to be directly placed in GPU’s memory hierarchy, such that GPU can access PMEM without software intervention. TrainingCXL introduces computing and checkpointing logic near the CXL controller, thereby training data and managing persistency in an active manner. Considering PMEM's vulnerability, ii) we utilize the unique characteristics of recommendation models and take the checkpointing overhead off the critical path of their training. Lastly, iii) TrainingCXL employs an advanced checkpointing technique that relaxes the updating sequence of model parameters and embeddings across training batches. The evaluation shows that TrainingCXL achieves 5.2× training performance improvement and 76% energy savings, compared to the modern PMEM-based recommendation systems. The manuscript will be available soon in IEEE Micro Magazine!
Donghyun's memory pooling with CXL work has been invited and accepted by IEEE Micro 2023
01.07.2023

Compute express link (CXL) has recently attracted great attention thanks to its excellent hardware heterogeneity management and resource disaggregation capabilities. Even though there is yet no commercially available product or platform integrating CXL into memory pooling, it is expected to make memory resources practically and efficiently disaggregated much better than ever before. In this paper, we propose directly accessible memory disaggregation that straight connects a host processor complex and remote memory resources over CXL’s memory protocol (CXL.mem). The manuscript will be available soon in IEEE Micro Magazine!
Keynote for Process-in-Memory and AI-semiconductor
12.13.2022


We gave another keynote regarding "Why CXL?" at Process-in-Memory and AI-semiconductor Strategic Technology Symposium 2022, hosted by two major ministries of Korea. This talk shared several insights as to why CXL can be one of the key technologies in hyper-scale computing and shows the differences between CXL 1.1, 2.0, and 3.0. In contrast to SC’22’s distinguished lecture (where I showed up heterogenous computing over CXL), this keynote focused more on CXL memory expanders and explained the corresponding infrastructure that most memory/controller vendors are unfortunately missing to catch up on nowadays. We open to discuss and welcome to contact for more on the future CXL technologies.
CXL panel meeting with Intel, Microsoft, LBNL, and keynote for SC'22!
11.21.2022


It was a great time to see the CXL consortium co-chair (AMD/Intel) at SC'22. Panel meeting (with Microsoft, Intel, LBNL) was also excellent in bringing up all the issues that high-performance computing (HPC) need to address in order to have CXL. In the distinguished lecture, we successfully demonstrated the entire design of the CXL switch and a CXL 3.0 system integrating true composable architecture. In particular, we showed up a new opportunity to connect all heterogeneous computing systems and HPC (having multiple AI vendors and data processing accelerators) and integrate them into a single pool. In addition, we brought what CXL 3.0 can do from a rack-scale interconnect technology (back-invalidation, cache coherence engine, fabric architecture with CXL, etc.) We hope that there is a chance to share more about our vision and CXL 3.0 prototypes at somewhere venues in the near future!
We will have the Opening Distinguished Lecture, introducing the future of CXL at RESDIS of SC'22 (Dallas)!
09.30.2022

Compute express link (CXL) has recently attracted significant attention thanks to its excellent hardware heterogeneity management and resource disaggregation capabilities. Even though there is yet no commercially available product or platform integrating CXL 2.0/3.0 into memory pooling, it is expected to make memory resources practically and efficiently disaggregated much better than ever before. In this lecture, we will check why existing computing and memory resources require a new interface for cache coherent and show up how CXL can put the different types of resources into a disaggregated pool. As a use case scenario, this lecture will show two real system examples, building a CXL 2.0-based end-to-end system straight connects a host processor complex and remote memory resources over CXL's memory protocol and a CXL-integrated storage expansion system prototype. At the end of the lecture, we also plan to introduce a set of hardware prototypes designed to support the future CXL system (CXL 3.0) as our ongoing project. We love to see you all in Texas, Dallas coming November!.
Check more: [ Lecure info. ] [ Program ]
Miryeong won the best paper award of Samsung, this year!
08.26.2022

Our team (Miryeong, Seungjoon, and Hyunkyu -- Miryeong is the first author) has won the Best Paper Award from Samsung for their paper "Vigil-KV: Hardware-Software Co-Design to Integrate Strong Latency Determinism into Log-Structured Merge Key-Value Stores". This work Vigil-KV, a hardware and software co-designed framework that eliminates long-tail latency almost perfectly by introducing strong latency determinism. To make Get latency deterministic, Vigil-KV first enables a predictable latency mode (PLM) interface on a real datacenter-scale NVMe SSD, having knowledge about the nature of the underlying flash technologies.

Vigil-KV at the system-level then hides the non-deterministic time window (associated with SSD's internal tasks and/or write services) by internally scheduling the different device states of PLM across multiple physical functions. Vigil-KV further schedules compaction/flush operations and client requests being aware of PLM’s restrictions thereby integrating strong latency determinism into LSM KVs. We prototype Vigil-KV hardware on a 1.92TB Datacenterscale NVMe SSD while implementing Vigil-KV software using Linux 4.19.91 and RocksDB 6.23.0. To the best of our knowledge, this is the first work that implements the PLM interface in a real SSD and makes the read latency of LSM KVs deterministic in a hardware-software co-design manner. We evaluate six Facebook and Yahoo scenarios, and the results show that Vigil-KV can reduce the tail latency of a baseline KV system by 3.19× while reducing the average latency on Get services by 34%, on average. Miryeong's Vigil-KV work takes the top among all the candidates this year. She also got $5000 cash prize. Congratulations!
Read more: [ Paper ] [ Video ] [ KAIST EE News (Korean) ] [ KAIST EE News (English) ]
CAMEL is invited by and will demonstrate two CXL platforms at the CXL Forum 2022
07.22.2022


CAMEL team is invited to demonstrate two hot topics about CXL memory disaggregation and storage pooling at CXL Forum 2022, which is the hottest session at Flash Memory Summit (led by the CXL Consortium and MemVerge). That deals with CXL updates from the CXL Consortium, Korea Advanced Institute of Science and Technology (KAIST), ARM, Astera Labs, Elastics.cloud, Hazelcast, Kioxia, Lenovo, Montage, NGD Systems, PhoenixNAP, Rambus, Smart Modular, Synopsys, University of Michigan TPP team, and Xconn. Our sessions will start on August 2nd, 4:40PM PT.
In the first session, entitled "CXL-SSD: Expanding PCIe Storage as Working Memory over CXL", we will argue that CXL is helpful in leveraging PCIe-based block storage to incarnate a large, scalable working memory. CXL could be a cost-effective, and practical interconnect technology that can bridge PCIe storage’s block semantics to memory-compatible byte semantics. To this end, we should carefully integrate the block storage into its interconnect network by being aware of the diversity of device types and protocols that CXL supports. This talk first discusses what mechanism makes the PCIe storage impractical and unable to be used for a memory expander. Then, it will explore all the CXL device types and their protocol interfaces to answer which configuration would be the best for the PCIe storage to expand the host’s CPU memory. In the second session, we will demonstrate our CXL 2.0 end-to-end system, including the CXL network and memory expanders. You can check more detailed information about who will be in the CXL forum and how to register to attend via Zoom through the given below link.
Check more: [ Full Program ] [ Register ]
Miryeong won the NVMW memorable paper award this year!
07.21.2022

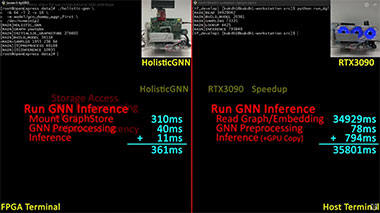
Our team (Miryeong, Donghyung, Sangwon -- Miryeong is the first author) has won the Memorable Paper Award from NVMW 2022 for their paper "HolisticGNN: Geometric Deep Learning Engines for Computational SSDs". This work deals with in-storage processing for large-scale GNN (graph neural network) using a novel computational SSD (CSSD) architecture and machine learning framework. Basically, it performs preprocessing of GNN in storage like near data processing (including sampling, graph conversion, etc.) and accelerates inference procedures over reconfigurable hardware. The team fabricates HolisticGNN’s hardware RTL and implements its software on an FPGA-based CSSD as well.
The NVMW memorable paper award is one of the prestige awards in non-volatile memory areas. It selects two papers published in the past two years in TOP-TIER venues and journals such as OSDI, SOSP, FAST, ISCA, MICRO, ASPLOS, and ATC. Among them, NVMW committee members not only examine the quality of all the top venue papers and corresponding presentations but also check the significant impact on non-volatile memory research fields. NVMW (founded in 2010) is a non-volatile memory workshop held annually by the Center for Memory and Recording Research (CMRR) and Non-Volatile Systems Laboratory (NVSL). For the past 13 years, there have been nine NVMW memorable paper awards. Miryeong's HolisticGNN work takes the top among all the candidates this year, and it is the first award that KAIST has achieved. She also got $1000 cash prize. Congratulations! You can check the history of all past winners here all the memorable paper award winners.
Our CXL 2.0-based Memory Expander and End-to-End System are introduced by the Next Platform’s headline
07.20.2022

The hyperscalers and cloud builders are not the only ones having fun with the CXL protocol and its ability to create tiered, disaggregated, and composable main memory for systems. HPC centers are getting in on the action, too, and in this case, the nextplatform is specifically talking about the Korea Advanced Institute of Science and Technology.

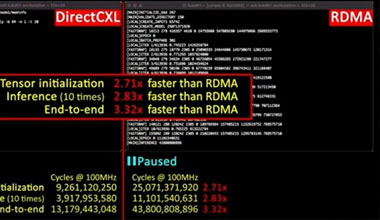
Researchers at KAIST’s CAMELab have joined the ranks of Meta Platforms (Facebook), with its Transparent Page Placement protocol and Chameleon memory tracking, and Microsoft with its zNUMA memory project, is creating actual hardware and software to do memory disaggregation and composition using the CXL 2.0 protocol atop the PCI-Express bus and a PCI-Express switching complex in what amounts to a memory server that it calls DirectCXL. The DirectCXL proof of concept was talked about it in a paper that was presented at the USENIX Annual Technical Conference last week, in a brochure that you can browse through here, and in a short video. (This sure looks like startup potential to the nextplatform .) -- Timothy Prickett Morgan
Read more: [ Headline ]
We have four studies that will be demonstrated at Hot series venues (HotChips and HotStorage)
06.20.2022


We have four research works that have been accepted from HotStorage’22 and HotChips34. The topics that our study deal with include i) CXL-enabled storage-integrated memory expanders (CXL-SSD), ii) an advanced system stack for high-performance ZNS, iii) a scalable RAID system for next-generation storage, and iv) large-scale GNN services through computational SSD and in-storage processing architecture. The works have been done by Miryeong Kwon, Donghyun Gouk, Hanyeoreum Bae, and Jiseon Kim. Congratulation! We are excited to see you all at HotStorage and HotChips this year! Please see the detail in our publication list [Publications]. The corresponding papers and slides will be updated soon.
Donghyun and Sangwoon's memory pooling with compute express link (CXL) has been accepted from USENIX ATC'22
04.30.2022


New cache coherent interconnects such as CXL have recently being attracted great attention thanks to their excellent capabilities of hardware heterogeneity management and resource disaggregation. Even though there is yet no real product or platform integrating CXL into memory disaggregation, it is expected to make memory resources practically and efficiently disaggregated much better than ever before.
In this paper, we propose direct accessible memory disaggregation, DirectCXL that directly connects a host processor complex and remote memory resources over CXL’s memory protocol (CXL.mem). To this end, we explore several practical designs for CXL-based memory disaggregation and make them real. As there is no operating system that supports CXL, we also offer CXL software runtime that allows users to utilize the underlying disaggregated memory resources via sheer load/store instructions. Since DirectCXL does not require any data copies between the host memory and remote memory, it can expose the true performance of remote-side disaggregated memory resources to the users. This year, the acceptance rate of USENIX ATC is 16%. Congratulations!!
Miryeong and Seungjoon KVS SSDs with strong latency determinism has been accepted from USENIX ATC'22
04.30.2022

We propose Vigil-KV, a hardware and software co-designed framework that eliminates long-tail latency almost perfectly by introducing strong latency determinism. To make Get latency deterministic, Vigil-KV first enables a predictable latency mode (PLM) interface on a real datacenter-scale NVMe SSD, being aware of the nature of the underlying flash technologies. Vigil-KV at the system-level then hides the non-deterministic time window (being associated with SSD internal tasks and/or write services) by internally scheduling the different device states of PLM across multiple physical functions. Vigil-KV further schedules compaction/flush operations and client requests being aware of PLM's restrictions thereby integrating strong latency determinism into LSM KVs. We implement Vigil-KV upon a 1.92TB NVMe SSD prototype and Linux 4.19.91, but other LSM KVs can adopt its concept. We evaluate diverse Facebook and Yahoo scenarios with Vigil-KV, and our evaluation shows that Vigil-KV can reduce the tail latency of a baseline KV system by 3.19x while reducing the average latency by 34%, on average.
This year, the acceptance rate of USENIX ATC is 16%. Congratulations!!
CAMEL's Large-Scale Computatioanl SSD Research Has Been Awarded from IITP
04.16.2022

CAMEL’s computational SSD research project is just awarded by the Institute of Information & Communications Technology Planning & Evaluation (IITP). The research will expose the practical but fundamental limits of the computational storage model, including the concept of Near-Data Processing (NDP), Smart SSD, and in-storage processing (ISP), and explore why computational SSDs have not been adopted in the industry by far. The research project will also suggest a breaking-through model and solutions that make computational SSDs be deployed in many computation domains ranging from enterprise-scale to cloud computing to data-centers.
This project includes the development of actual storage cards, hardware RTL, firmware, and large-scale I/O-centric operating systems, enabling a new model of generic computational SSDs. $5M (USD) solely coming from IITP will in total support CAMEL’s intelligent flash and computational storage projects for the next three years.
CAMEL uncovers The World-first CXL-based Memory Disaggregation IPs
03.05.2022

As the big data era arrives, resource disaggregation has attracted significant attention thanks to its excellent scale-out capability, cost efficiency, and transparent elasticity. Disaggregating processors and storage devices well does break the physical boundaries of data centers and high-performance computing into separate physical entities. In contrast to the other resources, it is non-trivial to achieve a memory disaggregation technique that supports high performance and scalability with low cost. Many industry prototypes and academic simulation/emulation-based studies explore a wide spectrum of approaches to realize such memory disaggregation technology and put significant efforts into making memory disaggregation practical. However, the concept of memory disaggregation has not been successfully realized by far due to several fundamental challenges.
CAMEL has prototyped the world-first CXL solution (POC) that directly connects a host processor complex and remote memory resources over computing express link (CXL) protocol. CAMEL’s solution framework includes a set of CXL hardware and software IPs, including CXL switch, processor complex IP, and CXL memory controller. The solution framework can completely decouple memory resources from computing resources and enable high-performance, fully scale-out memory disaggregation architecture.
Read more: [ White paper ]
Our Hardware and Software Co-Design for Energy-Efficient Full System Persistence is accepted by ISCA'22
03.03.2022
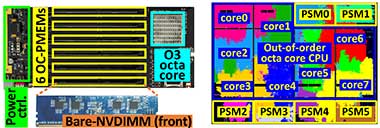
LightPC work argues that there is a better way to use PRAM than what Intel's Optane Persistent Memory solution uses. We implement a real persistent system and OS, which put all pure NVM DIMMs, NVM controllers, and RISC-V-based 03 octa-core CPU altogether. LightPC has NO volatile states at the runtime (e.g., DRAM) and guarantees that the target system doesn't lose any multi-threaded program execution, data in the heal and stack. In addition, you don't need to change anything on your application


ABSTRACT: We propose LightPC, a lightweight persistence-centric platform to make the system robust against power loss. LightPC consists of hardware and software subsystems, each being referred to as open-channel PMEM (OC-PMEM) and persistence-centric OS (PecOS). OC-PMEM removes physical and logical boundaries in drawing a line between volatile and non-volatile data structures by unshackling new memory media from conventional PMEM complex. PecOS provides a single execution persistence cut to quickly convert the execution states to persistent information in cases of a power failure, which can eliminate persistent control overhead. We prototype LightPC's computing complex and OC-PMEM using our custom system board. PecOS is implemented based on Linux 4.19 and Berkeley bootloader on the hardware prototype. Our evaluation results show that OC-PMEM can make user-level performance comparable with a DRAM only non-persistent system, while consuming 72% lower power and 69% less energy. LightPC also shortens the execution time of diverse HPC, SPEC and In-memory DB workloads, compared to traditional persistent systems by 1.6x and 8.8x, on average, respectively.
Our Hardware/Software Co-Programmable Framework for Computational SSDs to Accelerate GNNs is accepted by FAST'22
12.11.2021


Graph neural networks (GNNs) process large-scale graphs that consist of a hundred of billion edges. In contrast to traditional deep learnings, the unique behaviors of GNNs are engaged with a large set of graph and embedding data on storage, which exhibits complex and irregular preprocessing.
We propose a novel deep learning framework on large graphs, HolisticGNN that provides easy-to-use, near-storage inference infrastructure for fast, energy efficient GNN processing. To achieve the best end-to-end latency and high energy efficiency, HolisticGNN allows users to implement various GNN algorithms where the actual data exist and executes them directly from near storage in a holistic manner. It also enables RPC over PCIe such that the users can simply program GNNs through a graph semantic library without understanding the underlying hardware or storage configurations at all. We fabricate HolisticGNN's hardware RTL and implement its software on our FPGA-based computational SSD (CSSD). Our empirical evaluations show that the inference time of HolisticGNN outperforms GNN inference services using high-performance modern GPUs by 7.1× while reducing energy consumption by 33.2×, on average. This year, the acceptance rate of fast is 21%. For the entire history of KAIST, there are only three papers published by USENIX FAST, and we have all of them!! Congratulations!
Read more: [ News at KAIST ] [ Naver headline + 26 ] [ Press/Newspaper ]
Our PMEM-based in-memory graph study has been accepted from ICCD'21
08.20.2021

In this work, we investigate runtime environment characteristics and explore the challenges of existing in-memory graph processing. This system-level analysis includes results and observations, which are not reported in the literature with existing expectations of graph application users. To address a lack of memory space problem for big-scale graph analysis, we configure real persistent memory devices (PMEMs) with different operation modes and system software frameworks. Specifically, we introduce PMEM to a representative in-memory graph system, Ligra, and perform an in-depth analysis that uncovers the performance behaviors of different PMEM-applied in-memory graph systems. Based on the results, we also modify Ligra to improve the graph processing performance and data persistency. Our evaluation results reveal that Ligra, with our simple modification, exhibits 4.41× and 3.01× better performance than the original Ligra running on a virtual memory extension and conventional persistent memory.
Jie's optical network-based new memory for GPU has been accepted from MICRO'21
07.15.2021


Traditional graphics processing units (GPUs) suffer from the low memory capacity and demand for high memory bandwidth. To address these challenges, we propose Ohm-GPU, a new optical network based heterogeneous memory design for GPUs. Specifically, Ohm-GPU can expand the memory capacity by combing a set of high-density 3D XPoint and DRAM modules as heterogeneous memory. To prevent memory channels from throttling throughput of GPU memory system, Ohm-GPU replaces the electrical lanes in the traditional memory channel with a high-performance optical network. However, the hybrid memory can introduce frequent data migrations between DRAM and 3D XPoint, which can occupy the memory channel and increase the optical network traffic. To prevent the intensive data migrations from blocking normal memory services, Ohm-GPU revises the existing memory controller and designs a new optical network infrastructure, which enables the memory channel to serve the data migrations and memory requests, in parallel. Our evaluation results reveal that Ohm-GPU can improve the performance by 181% and 27%, compared to a DRAM-based GPU memory system and the baseline optical network based heterogeneous memory system, respectively. This year, the acceptance rate of MICRO is 22%. Congratulations!
Prof. Jung will discuss new memory technologies for HPC at ISC'21 Invited Program
05.20.2021


We will demonstrate novel applications that can be realized with emerging new memory technologies in high-performance computing and supercomputing systems at ISC'21 invited program. John Shalf who is the department of the head at Lawrence Berkeley National Laboratory will host Prof. Jung, Dr. Myung-Hee Na (the Vice President of SK Hynix), and Bruce Jacob (Keystone Professor of Electrical and Computer Engineering University of Maryland), and all we discuss the following issues: Non-volatile memory technologies are rapidly supplanting disk and tape. Furthermore, as NV memory performance is starting to match that of conventional volatile memory technologies, will the distinction between "storage" and "memory" starts to break down for future HPC and datacenter architectures? The panelists present a forward-looking vision for memory technologies (your choice of volatile or non-volatile or both) that covers emerging requirements and what are the most exciting/interesting memory technology developments that are on the horizon. 1) What are the driving requirements for the future in HPC and datacenters for the next decade, 2) How will both volatile and nonvolatile memory technologies evolve to meet those requirements? 3) How will the confluence of those two technologies change future system architectures (or how will these technologies increasingly differentiate to meet requirements?)
Dr. Jie Zhang will Join EECS of Peking University
05.01.2021

Congratulation to Dr. Jie Zhang! He passed all the reviews of Peking University, and got the official letter to join the School of Electronics Engineering and Computer Science (EECS) of Peking University as an assistant professor from this summer. Peking University is one of the top public universities in China, which is ranked #23 in QS World University Rankings 2021. Dr. Zhang joined CAMEL at 2014, when we were located at the University of Texas at Dallas. He moved together with us to Korea and achieved a Ph.D. at 2020. After graduation, he spends around two years as a Postdoc at KAIST. While Dr. Zhang pursues Ph.D. at CAMEL, his researches are published in the most top venues such as ISCA, ASPLOS, MICRO, HPCA, OSDI, and FAST. He is well-deserved, and we believe that he will go beyond. This is great for both Dr. Zhang and Peking University! Congratulations Dr. Jang, and the best wish for your new journey!
CAMEL has been awarded with software computing fundamental technology research from Ministory of Science and ICT
04.06.2021


Ministry of Science and ICT (IITP) awards CAMEL for AI-augmented Flash-based storage for self-driving car research. Specifically, CAMEL will perform the research of machine-learning algorithms that recover all runtime and device faults observed in automobiles. As the reliability of storage devices has a significant impact on self-driving automobiles, self-governing algorithms and fault-tolerant hardware architecture are significantly important. Prof. Jung as a single PI will be supported by around $1.6 million USD to develop lightweight machine-learning algorithms, hardware automation technology, and computer architecture for reliable storage and self-driving automobiles. We sincerely appreciate all anonymous reviewers and IITP staffs that gave us valuable comments and feedback!
Prof. Jung is awarded for ICT creative fusion research from Samsung Science & Technology Foundation
04.05.2021


The Samsung Science & Technology Foundation awards Prof. Jung's team (Prof. Shinhyun Choi and Wanyeong Jung) with $1.2 million USD for emerging graph neural network (GNN) research. This is the first research of the Samsung Science & Technology Foundation, which punches through all components from OS to computer architecture/circuits to materials. This multidisciplinary approach builds new resistive random access memory (ReRAM) array that contains multiple bits per cell and the history of the inputs in a natural way and integrates all the memory materials to a silicon-fabricated device and processor. As the PI, Prof. Jung will investigate OS and AI system frameworks to make GNN more efficient and be deployed in many computing areas easily. Congratulations!
Read more: [ News at EE KAIST (Korean) ]
Jie's Memory over Storage solution has been accepted from ISCA 2021
03.05.2021


Large persistent memories such as NVDIMM have been perceived as disruptive memory technology because they can maintain the state of a system even after a power failure and allow the system to recover quickly. However, overheads incurred by a heavy software-stack intervention seriously negate the benefits of such memories. First, to significantly reduce the software stack overheads, we propose HAMS, a hardware automated Memory-over-Storage (MoS) solution. Specifically, HAMS aggregates the capacity of NVDIMM and ultra-low latency flash archives (ULL-Flash) into a single large memory space, which can be used as a working or persistent memory expansion, in an OS-transparent manner. HAMS resides in the memory controller hub and manages its MoS address pool over conventional DDR and NVMe interfaces; it employs a simple hardware cache to serve all the memory requests from the host MMU after mapping the storage space of ULL-Flash to the memory space of NVDIMM. Second, to make HAMS more energy-efficient and reliable, we propose an "advanced HAMS" which removes unnecessary data transfers between NVDIMM and ULL-Flash after optimizing the datapath and hardware modules of HAMS. This approach unleashes the ULL-Flash and its NVMe controller from the storage box and directly connects the HAMS datapath to NVDIMM over the conventional DDR4 interface. Our evaluations show that HAMS and advanced HAMS can offer 97% and 119% higher system performance than a software-based hybrid NVDIMM design, while consuming 41% and 45% lower system energy, respectively. This year, the acceptance rate of ISCA is 18%. Congratulations!
Prof. Jung is awarded the best young researcher and granted with mid-scale research
03.02.2020

The National Research Foundation of Korea awards Prof. Jung (and his lab, CAMEL) the best young researcher. The award is given by evaluating the performance of the principal investigator and checking future potential to create a new research area. CAMEL will be given by around $1 million USD and supported by the National Research Foundation for the next five years. We will perform diverse low-latency storage system solutions and cross-layer optimizations for enterprise/datacenter flash devices. The future plan, in particular, includes zero-overhead journaling computational storage, file system delegation, lock-free storage systems, hardware-accelerated operating system, and reliability management in enterprise servers. We sincerely appreciate all anonymous reviewers and NRF staffs that gave us valuable comments and feedback!
Wonil joins Hanyang University as a tenure-track professor
03.02.2021


Dr. Wonil Choi joins Hanyang University this year as an assistant professor. He joined CAMEL when we were located at the University of Texas at Dallas (2013). After CAMEL moved to Korea (Yonsei University), he kept pursuing a Ph.D. at PennState (co-advised with Dr. Kandemir). He published 19 research papers with us at top-venues in computer architecture and operating systems areas. We remember him as an excellent student and active member in terms of not only research but also all other perspectives. At the end of his Ph.D. journey, he decides to join Hanyang University. His main research area is flash devices, storage, and firmware and file systems. All the best for his new position! Hope that this job will bring some fun and success to his life. Congratulation!
Read relaxation for 3D NAND work has been accepted from HPCA 2021
11.19.2020

The adoption of 3D NAND has significantly increased the SSD density; however, 3D NAND density-increasing techniques, such as extensive stacking of cell layers, can amplify read disturbances and shorten SSD lifetime. From our lifetime-impact characterization on 8 state-of-the-art SSDs, we observe that the 3D TLC/QLC SSDs can be worn-out by low read-only workloads within their warranty period since a huge amount of read disturbance-induced rewrites are performed in the background. To understand alternative read disturbance mitigation opportunities, we also conducted read-latency characterizations on 2 other SSDs without the background rewrite mechanism. The collected results indicate that, without the background rewriting, the read latencies of the majority of data become higher, as the number of reads on the data increases. Motivated by these two characterizations, in this paper, we propose to relax the short read latency constraint on the high-density 3D SSDs. Specifically, our proposal relies on the hint information passed from applications to SSDs that specifies the expected read performance. By doing so, the lifetime consumption caused by the read-induced writes can be reduced, thereby prolonging the SSD lifetime. The detailed experimental evaluations show that our proposal can reduce up to 56\% of the rewrite-induced spent-lifetime with only 2\% lower performance, under a file-server application. The acceptance rate of ASPLOS this year is 18%
Our collaborative research related to 3D NAND has been accepted from HPCA 2021
10.28.2020

The high-density of 3D NAND-based SSDs comes with longer write latencies due to the increasing program complexity. To address this write performance degradation issue, NAND flash manufacturers implement a 3D NAND-specific full-sequence program (FSP) operation. The FSP can program multiple-bit information into a cell simultaneously with the same latency as the baseline program operation, thereby dramatically boosting the write performance. However, directly adopting the (large granularity) FSP operation in SSD firmware can result in a lifetime degradation problem, where small writes are amplified to large granularities with a significant fraction of empty data. This problem cannot completely be mitigated by the DRAM buffer in the SSDs since the ``sync" commands from the host prevent the DRAM buffer from accumulating enough written data. To solve this FSP-induced performance/lifetime dilemma, in this work, we propose GSSA (Generalized and Specialized Scramble Allocation), a novel written-data allocation scheme in SSD firmware, which considers both various 3D NAND program operations and the internal 3D NAND flash architecture. By adopting GSSA, SSDs can enjoy the performance benefits brought by the FSP without excessively consuming the lifetime. Our experimental evaluations reveal that GSSA can achieve the throughput and the spent-lifetime of the best-performance and best-lifetime single granularity schemes, respectively. The acceptance rate of HPCA this year is 24%
We will have a Keynote speech for Samsung Open Source Conference 2020
09.21.2020

Samsung Open Source Conference is currently the largest Open Source conference in Korea organized by Samsung Electronics. The conference has been held every year as a venue for more than 2,000 participants, such as software developers, students, and startup communities, to share their varied knowledge and experiences acquired from the Open Source field. We will have a Keynote speech that introduces diverse open-source hardware platforms, including processor IPs (RISC-V), memory controller IPs (SoftMC), AI accelerator IPs (NVDLA), and NVMe storage controller IPs (OpenExpress). It also shows what KAIST does for open source community, and what the industry/academia and products will take advantage of open-source hardware. Specifically, we will show an ecosystem of RISC-V and some other exciting projects that utilize open hardware such as automobile perception computing unit (Autoware.IO), open robotics (PULP), high-performance supercomputers (European Processor Initiative), and datacenters (XuanTie910 RISC-V).
CAMELab has got attention from diverse major press reports
08.05.2020

OpenExpress has debuted to many major press reports such as Chosun (조선일보), Donga (동아일보), Hankyung (한국경제), and more than 50+ journals at the headlines of NAVER news and DAUM news. OpenExpress is a set of NVMe controller hardware IP modules and firmware for future fast storage class memory research with storage and memory communities. The cost of 3rd party's IP cores (maybe similar to OpenExpress ) is around $100K (USD) per single-use source code, but OpenExpress is free to download for academic research purposes. For the detailed new scraps (지면) and on-line articles, please check the follow:
[ KR news 45+ (Naver) ] [ KR major print press/newspaper 5+ ]
Gyuyoung's PRAM-based SSD work has been accepted from ICCAD'20
07.17.2020
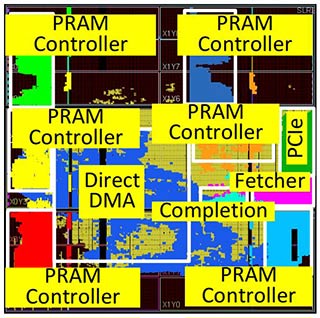

We propose Automatic-SSD that converts all storage management logic into hardware, which enable energy efficient, high performance fast memory based block storage. To achieve low operating power, Automatic-SSD directly reads or writes host-side data to underlying backend storage media without internal DRAM caches. To realize such DRAM-less approach with better performance and make it more energy efficient, Automatic-SSD also removes the internal processor(s) and firmware execution therein by fully automating the backend request management and data transfers over all pipelined hardware modules. We prototype Automatic-SSD on a middle-end FPGA custom board, employing massive numbers of phase change memories as representative of new memory technologies. Our evaluation results show that, compared to a conventional firmware-based approach, Automatic-SSD shows up 28.8× and 25.4× better bandwidth and latency behaviors, respectively, while consuming only 5% of the total energy, on overage.
Jie's work removing page victimiation overhead in NVMe, has been accepted from IEEE CAL'20
06.15.2020

Host-side page victimizations can easily overflow the SSD internal buffer, which interferes I/O services of diverse user applications thereby degrading user-level experiences. To address this, we propose FastDrain, a co-design of OS kernel and flash firmware to avoid the buffer overflow, caused by page victimizations. Specifically, FastDrain can detect a triggering point where a near-future page victimization introduces an overflow of the SSD internal buffer. Our new flash firmware then speculatively scrubs the buffer space to accommodate the requests caused by the page victimization. In parallel, our new OS kernel design controls the traffic of page victimizations by considering the target device buffer status, which can further reduce the risk of buffer overflow. To secure more buffer spaces, we also design a latency-aware FTL, which dumps the dirty data only to the fast flash pages. Our evaluation results reveal that FastDrain reduces the 99th response time of user applications by 84%, compared to a conventional system.
Our acceleration NVMe I/O processing work has been accepted from USENIX ATC'20
04.27.2020

NVMe is widely used by diverse types of SSDs and non-volatile memories as a de-facto fast I/O communication interface. Industry secures their own intellectual property (IP) for high-speed NVMe controllers and explores software stack challenges atop future fast NVMe devices. Unfortunately, such NVMe controller IPs are often inaccessible to academia. The research community however requires an open-source hardware framework to build new storage stack and controllers for the fast NVMe devices. We present OpenExpress, a fully hardware automated NVMe controller that has no software intervention to process concurrent I/O requests while supporting scalable data submission, rich outstanding NVMe command queues, and submission/completion queue management. The acceptance rate of ATC 2020 is around 18%.
Jie's GPU multi-processor with new flash has been accepted from ISCA'20
03.04.2020

We propose ZnG, a new GPU-SSD integrated architecture, which can maximize the memory capacity in a GPU and address performance penalties imposed by an SSD. Specifically, ZnG replaces all GPU internal DRAMs with an ultra-lowlatency SSD to maximize the GPU memory capacity. ZnG further removes performance bottleneck of the SSD by replacing its flash channels with a high-throughput flash network and integrating SSD firmware in the GPU’s MMU to reap the benefits of hardware accelerations. Although flash arrays within the SSD can deliver high accumulated bandwidth, only a small fraction of such bandwidth can be utilized by GPU’s memory requests due to mismatches of their access granularity. To address this, ZnG employs a large L2 cache and flash registers to buffer the memory requests. Our evaluation results indicate that ZnG can achieve 7.5× higher performance than prior work. The acceptance rate of ISCA 2020 is 18%. Congratulations, Jie!
Miryeong, Donghyun, and Changrim's DC-Store work has been accepted from FAST'20
12.12.2019


We propose DC-store, a storage framework that offers deterministic I/O performance for a multi-container execution environment. DC-store’s hardware-level design implements multiple NVM sets on a shared storage pool, each providing a deterministic SSD access time by removing internal resource conflicts. In parallel, software support of DC-Store is aware of the NVM sets and enlightens Linux kernel to isolate noisy neighbor containers, performing page frame reclaiming, from peers. We prototype both hardware and software counterparts of DC-Store and evaluate them in a real system. The evaluation results demonstrate that containerized data-intensive applications on DC-Store exhibit 31% shorter average execution time, on average, compared to those on a baseline systemThe acceptance rate of FAST 2020 is 16%. Congratulations, Miryeong!
Jie&Miryeong's scalable parallell flash firmware research has been accepted from FAST 2020
12.12.2019
NVMe is designed to unshackle flash from a traditional storage bus, by allowing hosts to employ many threads to achieve higher bandwidth. While NVMe enables users to fully exploit all levels of parallelism offered by modern SSDs, current firmware designs are not scalable and have difficulty handling a large number of I/O requests in parallel due to its limited computation power and many hardware contentions. We propose DeepFlash, a novel manycore-based storage platform that can simultaneously process more than a million I/O requests in a second while hiding the long latency imposed by internal flash media. Inspired by a parallel data analysis system, we design the firmware based on many-to-many threading model that can be scaled horizontally. The proposed DeepFlash can extract the maximum performance of the underlying flash memory complex by concurrently executing multiple firmware components across many cores within the device. To show its extreme parallel scalability, we implement DeepFlash on a many-core prototype processor that employs dozens of lightweight cores, analyze new challenges from parallel I/O processing, and address the challenges by applying concurrency-aware optimizations. Our comprehensive evaluation reveals that DeepFlash can serve around 4.5 GB/s, while minimizing the CPU demand on microbenchmarks and real server workloads. The acceptance rate of FAST 2020 is 16%. Congratulations, Jie!
Wonil's consolidated flash cache has been accepted from ASPLOS 2020
11.19.2019

Consolidating multiple workloads on a single flash-based storage device is now a common practice. We identify a new problem related to lifetime management in such settings: how should one partition device resources among consolidated workloads such that their allowed contributions to the device's wear (resulting from their writes including hidden writes due to garbage collection) may be deemed fairly assigned? This problem is made challenging by the complex relationship between hidden writes and allocated flash capacity. We first clarify why the write attribution problem is non-trivial. We then present a technique for it inspired by the Shapley value, a classical concept from cooperative game theory, and demonstrate that it is accurate, fair, and feasible. We next consider how to treat an overall "write budget" (i.e., total allowable writes during a given time period) for the device as a first-class resource worthy of explicit management. Towards this, we propose a novel write budget allocation technique (accompanied by a complementary capacity partitioning technique). Finally, we construct a dynamic lifetime management framework for consolidated devices by putting the above elements together. The acceptance rate of ASPLOS 2020 is 18%. Congratulations, Wonil!
Jie and Gyuyoung's work (co-first author) has been accepted from HPCA 2020
11.07.2019

General purpose hardware accelerators have become major data processing resources in many computing domains. However, the processing capability of hardware accelerations is often limited by costly software interventions and memory copies to support compulsory data movement between different processors and solid-state drives (SSDs). This in turn also wastes a significant amount of energy in modern accelerated systems. In this work, we propose, DRAM-less, a hardware automation approach that precisely integrates many state-of-the-art phase change memory (PRAM) modules into its data processing network to dramatically reduce unnecessary data copies with a minimum of software modifications. We implement a new memory controller that plugs a real 3x nm multi-partition PRAM to 28nm technology FPGA logic cells and interoperate its design into a real PCIe accelerator emulation platform. The acceptance rate of HPCA-26 is 19%. Congratulations, Jie and Gyuyoung!
Sungjoon's Faster than Flash work has been accepted from IISWC'19
08.15.2019


Emerging storage systems with new flash exhibit ultra-low latency (ULL) can address performance disparities between main memories and conventional solid state drives (SSDs) in memory hierarchy. Considering the low-latency characteristics, new types of I/O completion methods (polling) and storage stack architecture (SPDK) are proposed. While these new techniques are expected to take costly software interventions off the critical path in ULL SSDs, there is unfortunately no study to quantitatively analyze system-level characteristics and challenges by putting the techniques with real ULL devices. In this work, we first comprehensively perform empirical evaluations with 800GB ULL SSD prototypes and characterize ULL behaviors by considering a wide range of I/O path parameters such as different queues and access patterns. We then analyze the efficiencies and challenges of the polled-mode and hybrid polling I/O completion methods (added into Linux 4.4 and 4.10, respectively) and compare them with the efficiencies of a conventional interrupt-based I/O path. In addition, we revisit the common expectation of the SPDK by examining different types of system resources and performance parameters. We then demonstrate the challenges of ULL SSDs in a real SPDK-enabled server-client system. Based on the performance characteristics that this study uncovers, we also discuss several system implications, which are required to take a full advantage of ULL SSD in the future.
Wonil's dominant resource fairness has been accepted from USENIX HotStorage'19
04.18.2019


We believe that, along with bandwidth and capacity, lifetime is also a critical resource and it needs to be explicitly and carefully managed in consolidated flash systems. To manage these diverse resources and fairly divide them across competing users in a consolidated flash device, we propose to employ dominant resource fairness (DRF). Using DRF, we empirically show that, managing only bandwidth and capacity shortens the device lifetime. In adapting DRF to the flash storage context, we identify a few challenges and present simple heuristics to overcome them. We also discuss possible design choices, which will be fully explored in future work.
Wonil's GC scheduling work has been accepted from IEEE TCAD
04.15.2019

Garbage collection (GC) and resource contention on I/O buses (channels) are among the critical bottlenecks in solid-state disks (SSDs) that cannot be easily hidden. Most existing I/O scheduling algorithms in the host interface logic (HIL) of state-of-the-art SSDs are oblivious to such low-level performance bottlenecks in SSDs. As a result, SSDs may violate quality of service (QoS) requirements by not being able to meet the deadlines of I/O requests. In this paper, we propose a novel host interface I/O scheduler that is both GC aware and QoS aware. The proposed scheduler redistributes the GC overheads across non-critical I/O requests and reduces channel resource contention. Our experiments with workloads from various application domains revealed that the proposed client-level SSD scheduler reduces the standard deviation for latency by 52.5% and the worst-case latency by 86.6%, compared to the state- of-the-art I/O schedulers used for the HIL. In addition, for I/O requests smaller than a superpage, the proposed scheduler avoids channel resource conflicts and reduces latency by 29.2% in comparison to the state-of-the-art I/O schedulers. Furthermore, we present an extension of the proposed I/O scheduler for enterprise SSDs based on the NVMe protocol.
History before KAIST (2013.08~2019.02) HERE
